ジップの法則
(インプレス社発行の「インターネット・マガジン」6月号に載っていた記事なので、お読みになった方もいるかもしれないが‥‥)
昔、ジップという人が、英単語の出現率を調べたのだそうだ。ジェームズ・ジョイスの有名な「ユリシーズ」という長い小説に使われた260,430個の英単語と、いくつかの新聞記事の43,989個の英単語を洗い出し、その出現頻度を調べたのだという。
すると次のような順位になったのだそうだ。
(1) the
(2) of
(3) and
(4) to
さらに興味深いことには、第1位のtheは全体の出現数の約10%を占め、第2位のofは5%、第3位のandは3.3%という結果になったのだという。
この数値を分析したジップは、ある法則性を見つけた。それを式で書くと、次のようになる。
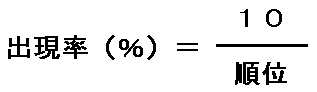
これが「ジップの法則」と言われるものなのだそうだ(けっこう知られたものなのかもしれないが、私は初めて知った)
この法則は英単語だけでなく、いろいろなものに適用できるのだという。
「インターネット・マガジン」1999年6月号、310ページの「後藤滋樹の『新・社会楽』第53回『不思議な法則』」(後藤滋樹氏は早稲田大学理工学部情報学科の先生)では、様々な例をあげている。(後藤氏も、J.R.ピアース著「記号・シグナル・ノイズ」白揚社1988等を引用している)
「多くの国の都市の人口とその大きさの順位」とか、「インターネットのドメイン別のホスト数」とか、「人気Webのアクセス頻度の順位とそのヒット数」などが、きれいにジップの法則にあてはまるのだそうだ。
卑近な例としては、映画の観客動員数もそうだという。具体例として、1998年12月23日の京都エリアでの映画館の情報をあげている。結果は次の通りだ。
第1位 アルマゲドン 4,300人
第2位 ジョー・ブラックをよろしく 2,700人
第3位 6デイズ/7ナイツ 1,500人
第2位が第1位の約半分の人数、第3位が1/3となるのは、ジップの法則にほかならないのだそうだ。
私は「なるほどー!」と感心したのだが、本当にそうなっているのだろうか?
自分で確かめてみないと気がすまないたちの私は、さっそく、実際の例で確かめてみた。
私が登録している「ReadME」という読み物(テキスト)中心のホームページのランキングがある。(こちら「[ReadMe!] Daily Report」をクリックすると、そのページにつながる)
↑をクリックすると表示されるデータは日替わりなので、毎日同じではないが、ここで表示されたデータをプリントアウトし、それを表計算ソフトに入力して分析してみたら、上位の方で少し違った傾向はあるものの、全体としてみると確かにジップの法則にあてはまるようだ。
完全にジップの法則に従った場合の数値を1として、各順位の数値を分析してみると、上位10位より下のあたりにくれば、その誤差は0.2以内の範囲に収まる。
私のHPは、このランキングでは、だいたい300位台を上下しているので、出現率としては「10÷300」ということになり、0.03%程度ということになる。これも実際の数値を入れて計算してみるとあてはまっているようだ。
これが世の中全ての現象にあてはまるということはありえないだろうが、ある程度データ数が大きくなった場合は、ジップの法則に近い結果になるのかもしれない。
学校や会社などで扱うデータで試してみるのも面白いかもしれない。
 ホームページに戻る
ホームページに戻る うんちく目次へ
うんちく目次へ